conda install tensorflow followed by conda install keras, or if that does not work, replace conda by pip, and/or sudo pip if you installed Python as root).sudo pip install --upgrade keras
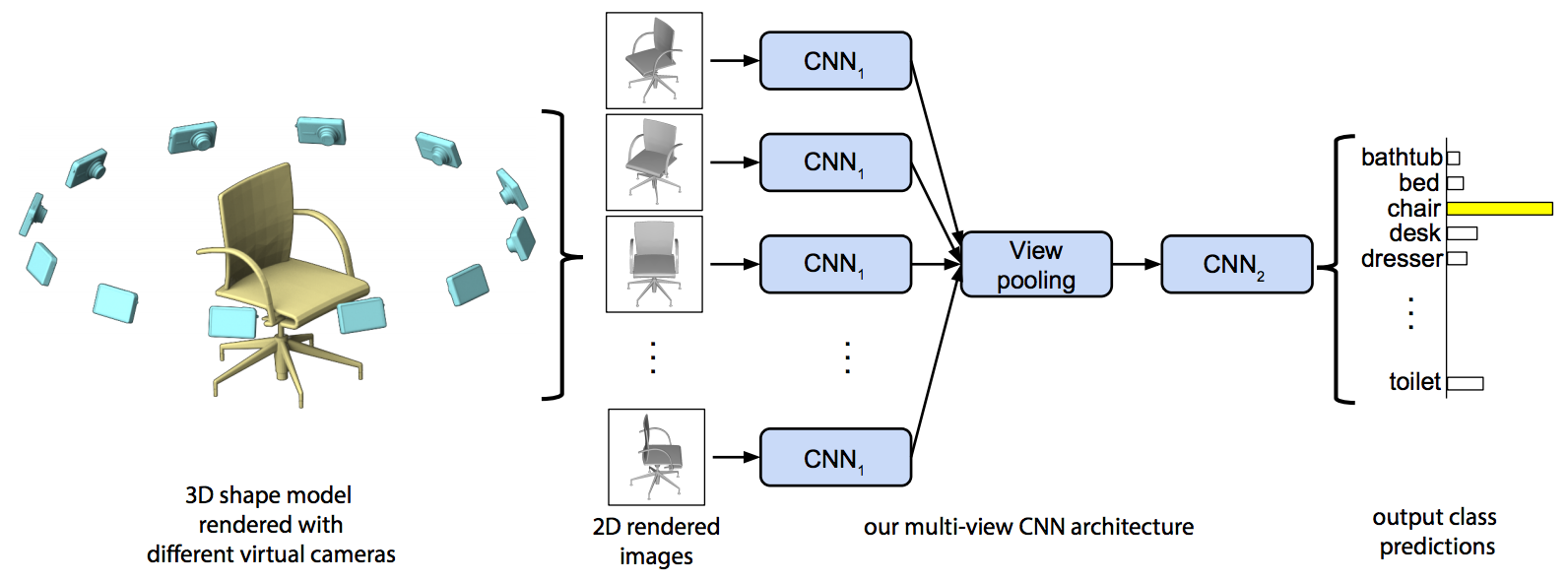
modelnet40_generator. This function returns a generator, which produces training/testing images and their corresponding classes for ModelNet-40. Please see the docstring for modelnet40_generator for extensive documentation on how it works, and the bottom of the module for an example of how to use it.model.fit_generator() with arguments that are the ModelNet-40 training and testing set generators. Make sure this initial fine-tuning network runs (but you do not need to run it until convergence). Note: you will want to use the categorical_crossentropy loss.n. This could be done for example by collecting n elements from the ModelNet-40 generator, and concatenating them along the batch size dimension (dimension 0 in our case). The produced data should be in the same format as the original ModelNet-40 generator, just with a larger batch size. Use the "batching" generators for training and testing to improve the efficiency.fit_1view.py.fit_nview.py, which implements the multi-view classifier.
resnet = keras.applications.resnet50.ResNet50(include_top=False)
resnet = keras.models.Model(resnet.input, resnet.layers[STOP_LAYER].output)
Here STOP_LAYER is the layer at which to truncate CNN1. In your writeup, report (D) at which layer you decided to truncate CNN1. You may want to see the ResNet paper, Table 1 for the list of layers, and in your code you can also print resnet.layers for the list of layers. Next, you can construct a list of Input instances to represent the 12 input images for the multiple views, and pass each of these through your shared-parameter CNN1 (resnet(x) in the functional API will apply to tensor x). For details of how to do this, see the sections about multiple inputs in the Keras functional API.single=False to indicate multi-view data is being generated.yourname_project1.zip. Please include your source code for both of part 1 and part2, as fit_1view.py, fit_nview.py, and include the modelnet40.py (so your submission can be run as-is). Please also include a text file writeup as writeup.txt briefly describing how to run the two programs (if any arguments are needed), and the bolded points that were to be reported (A-E), as mentioned above.